Machine Learning and ML Patterns
Machine learning is to program computers to improve a performance standard using example data or experience. Learning is used when humans are unable to explain their expertise (speech recognition), Solution changes in time (routing on a computer network), Solution needs to be adapted to particular cases (user biometrics)
What we’re talking about is “learning”:
Given a Dataset D, a task T, and a performance measure M, a computer system is said to learn D to run the task T if, after learning the system performance on T progresses as measured by M. In other words, the learned model supports the system to perform T better than no learning.
A classic Example

Recognizing text may be tough like S & 5 similarly O & 0.
An Example Application
The emergency room of the hospital measures n the number of variables (e.g. blood pressure, age, etc.) of the newly-received patients. A decision should be taken if the new patient is to be included in the intensive care unit. Due to the high cost of the ICU, patients who can survive less than a month will receive a higher priority.
Problem: Predict high-risk patients and discriminate against low-risk patients.
Another Example
The credit card company receives thousands of requests for new cards. Each application contains information about the candidate age, marital status, annual salary, outstanding debts, punctuation,
Problem: Deciding to approve or classify the application in two categories, approving it and not accepting it.
More Examples
Recognize patterns: Facial identities or facial expressions, handwritten or spoken words, medical images.
Model generation: Image generation or motion sequences.
Recognize anomalies: Unusual patterns of sensor readings in a nuclear power plant or an unusual sound in the car’s engine.
Prediction: Future stock prices or exchange rates
Some Web Examples
The web contains a lot of data. Tasks with very large datasets often use machine learning, especially if the data is noisy or unstable.
Spam filtering, fraud detection: The enemy adapts, we must adapt to it as well.
Recommendation systems: lots of noisy data. Recommend valued data.
Request Information: Search for documents or images with similar content.
Data visualization: Displaying a massive database in the revealing form.
Learning Algorithm
Learning: Learn the model using training data.
Testing: Test the model using unnoticed test data to evaluate model accuracy.


Learning Patterns
- Supervised Learning
- Classification
- Regression
- Unsupervised Learning
- Clustering
- Reinforcement Learning
- Associative RL
- Non-Associative RL
Supervised Learning
Classification
Predicts categorical class labels. Classifies data based on the training set and the values (class labels) in a classifying attribute and uses it in classifying new data. Credit scoring. The separation between low-risk and high-risk clients from their income and savings.
Classification Applications
- Pattern recognition
- Face detection and recognition
- Character recognition
- Speech recognition
- Sensor fusion: Associate various modalities; e.g., visual (lip image) and sound for speech
- Medical diagnosis
Regression
Example: Price of a used car
x: car attributes
y: pricey = g (x | θ ) g ( ) model, θ parameters
Regression Applications
Navigating a car: Angle of the steering wheel & Kinematics of a robot arm
α1= g1(x,y)
α2= g2(x,y)

- Prediction of future cases
- Use the regulation to guess the output for upcoming inputs
- Knowledge extraction
- Learning a rule from data
- Compression
- Finding a rule simpler than the data it explains
- Outlier detection
- Exclusions that are not enclosed by the rule, e.g., fraud
Unsupervised Learning
Learning “what normally happens”, No predefined output
Clustering: Grouping similar instances
Example applications
- Customer segmentation in CRM
- Image compression: Colour quantization
- Bioinformatics: Learning motifs
Clustering
Clustering is a methodology for finding similar collections of data that are called clusters. Groups data instances that are similar to each other (closed) in a cluster and very different (remote) data instances in one of the other different clusters. Clustering is an unsupervised learning task because there are no class values that represent a particular group of examined data instances. which in case of supervised learning.
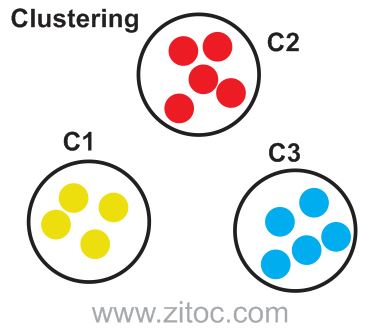
Illustration
Data collection consists of three natural groups of data points, namely 3 natural clusters.
What is clustering for?
Let us understand some real-life examples
Example: Groups of people of similar size who collect T-shirts “small “, “medium” and “big “. Tailor-made for each person: too expensive. One size: not suitable for everyone.
Example: In marketing, fragment customers by their similarities, to do directed marketing.
Example: About the collection of text documents, we want to organize them according to their content representations, which produce a hierarchy of topics. Clustering is one of the most necessary data mining techniques. It has a long history and is used in almost all areas, for example, medicine, psychology, sociology, botany, biology, marketing, insurance, libraries, etc.
In recent years, due to an accelerated increase in online documents, the text clustering becomes essential.
ASPECTS OF CLUSTERING
- A clustering algorithm:
Partitioning clustering
Hierarchical clustering
- A distance (similarity, or dissimilarity) function
- Clustering quality: The quality of a clustering result depends on the algorithm, the distance function, and the application.
Reinforcement Learning
Reinforcement learning is supervised learning in which limited information of the desired outputs is known but Complete knowledge of the environment is not available; only basic benefit or reward information. In other words, a critic instead of a teacher leads the learning process. Reinforcement learning has roots in experimental studies of animals to learn, teaching a dog through positive (“Good dog “, something to eat) and negative (“Bad Dog “, nothing to eat) reinforcement.
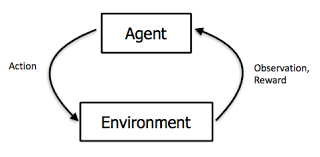
Associative
Associating action and stimuli. In other words, an incentive to draw action to develop the reinforcement information received from the environment.
Non-associative
Choose an action instead of actions associated with stimuli. The only input acknowledged from the surroundings is reinforcement information. Examples include genetic algorithms
The reinforcement signal can be any signal that evaluates the actions of the learning system, not only a sign of success/failure that it takes in real values often, and the learning objective is to maximize its expected value. The critic does not tell the learning system directly on how to change his actions. Reinforcement learning algorithms are selection processes. There must be a variation in the process of generating actions so that the effects of the alternative actions can be compared with the best option.